如何通过延迟时间“操纵”现场声效
现代音响系统力求为所有听众提供最佳的声效和语言清晰度,它们绝非“插电 - 开机”这么简单,音响工程师们需要付出巨大努力才能让整个系统工作在理想状态。

听得响
衰减
人们听到的声压级大小除了跟声源本身发出的声音大小有关,还和与声源之间的距离有直接联系。声音并不能无限的扩散下去,而是每传出一倍距离就衰减大约 6dB(点声源)。
一个声压级为 adB 的点声源发出的声音传播 dm 远后的声压级可以用这个公式估算:
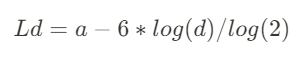
传播衰减会导致听音体验和听众所处的位置有关,特别是在大型厅堂或露天演唱会等场景。

信噪比
另外,当声源和背景噪声的差异 - 也就是信噪比低于合理范围,比如 15dBA 以上,语言清晰度也会开始大幅下降。
单纯提高声源的声压级并不能完全解决问题,除了要考虑设备本身的发声性能,这样做还必然会导致更靠近声源的人暴露在过大的声压级下。
方案
人们很快想到了解决方案 - 只要在大型场景布置数量更多的扬声器就足以弥补声源能量的不足。
声墙:最开始的方案总是简单粗暴,就和字面意思一样,人们把几十甚至上百只音箱堆成一堵墙,以恐怖的功率输出声音。但这种方式并没有沿用太久,抛开尺寸、重量和成本等因素,简单的堆叠并不能很好解决声音覆盖问题,反而因为太多音箱互相干扰导致现场听感不佳。
线阵列:1957 年,著名声学专家哈里·奥尔森(Harry Olson)在他的经典著作《声学工程》中首次介绍了随着频率的增加,波束会收窄的线阵效应。并将线阵列的概念应用在柱形扬声器的开发中。1983年,扬声器设计大师约瑟夫·达波利托(Joseph D'Appolito)进一步认为可以在水平定向箱体中使用多频段线阵单元。
但直到上世纪 90 年代,人们才最终认识到,声音在水平面上并不存在破坏性的干涉,更多是垂直面上相位的叠加,只需很少的扬声器组成阵列就能得到很好的声压级辐射和比较平滑的频率响应。
人们将一系列型号相同或相近的扬声器以特定角度紧密垂直排列,并确保扬声器发出信号的相位相同,就得到了近似一条竖线的线阵列声源。

© Ville Hyvönen
补音扬声器:线阵列以其优异的指向性,特别适合需要远距离扩声的场景。作为一个线声源,它的声衰减速率比传统扬声器慢了一倍 - 距离增加一倍,总的声压级大约只降低 3dB。尽管如此,线阵列仍有投送极限,更不用说并不是每个地方都能吊装相对庞大的阵列。这时,人们在声场的中部或后部额外增加扬声器,起到补音的作用。

吊装在顶部的补音扬声器
声音大小的问题解决了,但更多的扬声器,更复杂的场景,让人们不得不面对另一个棘手的问题。
延迟
声速
声波在不同介质中传播的速度大相径庭,在常温常压下,声波在空气中的传播速度约为 340m/s,这是我们熟悉的声速。
而声音以振动的方式从扬声器发出前,以电信号的形式在缆线中传播,电信号的速度和光速相当,都是 300000km/s。

比如,电信号在 100m 缆线中完成传输只需约 0.003μs,而声音在空气中传播同样距离需要约 290ms。
这也导致多只扬声器分布在不同位置时,它们发出的声音几乎不可能同时到达同一个点。
哈斯效应
早在 1851 年,著名科学家约瑟夫·亨利(Joseph Henry,就是发现电感和发明继电器的那位)就在《关于直达声和反射声的感知极限》中讨论了人对不同波次声音的感知问题。
亥尔姆·哈斯(Helmut Haas)在前人基础上深入研究,1949 年,他在自己的博士论文中对所谓的“优先效应”加以论述。

- 人类总是基于首先听到的声音判断声音的方向;
- 若第二处声源不晚于第一处声源 35ms 到达,且声压级更大,则有助于提高语言清晰度;
- 若第二处声源在第一处声音到达 35ms 之后才被人听到,那它听上去就是完全是另一个声音(回声),听者能清楚区分两个声音的方向;
- 声源之间的声压级差也会一定程度影响人的感知。在同一位置,补音扬声器的声压级比前置主扬声器适当高出 6 dBA,可以在声效和成本之间取得不错的平衡,但声压级差最大不宜超过 10dBA,否则将转移听众的注意力。
哈斯效应在扩声系统、声氛围营造等领域有非常重要的指导意义,了解这些特性,人们学会了“操控”声音。
范例
想象一下自己正坐在一个礼堂中听报告或观看演出。

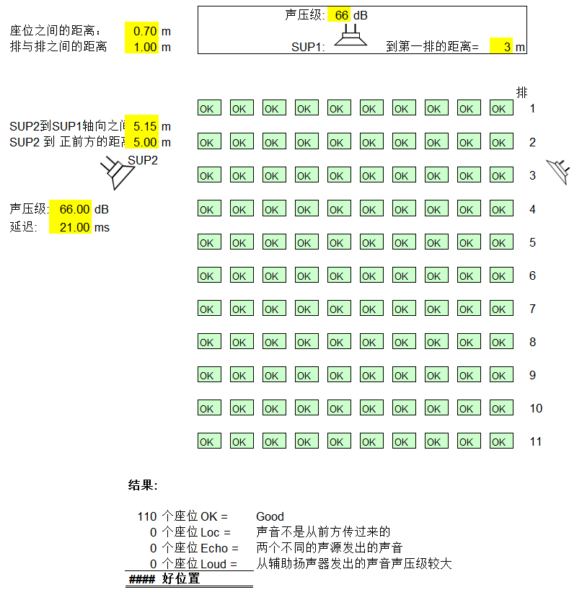
我们假设就是下图第三排左一的橙色框位置。
报告厅中的主扬声器 SUP1 和补音扬声器 SUP2 发出的都是标准的 66dBA @ 1m 的声压级。
你距离舞台的主扬声器 SUP1 的直线距离是 5.9m,你的旁边刚好有一只补音扬声器,它离你只有 2m。
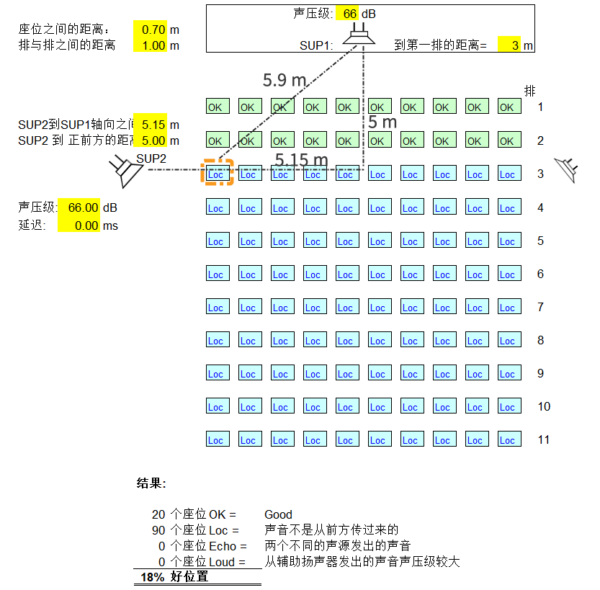
结合距离和声速不难算出来:SUP1 到达你的位置需要约 17.4ms,而 SUP2 的声音只需约 5.9ms。
再根据前面的声压级传播衰减公式还能算出:SUP1 到达你位置的声压级约 50.6dBA,而 SUP2 则是 60.0dBA。
结果就是:SUP1 的声音会比 SUP2 迟 11.5ms 到达你的位置,并且声音也比 SUP2 低 9.4 dBA。你将看着前方的演出却听见声音从侧面传来。
这种体验想必不会太好!
我们可以给 SUP2 一个 17ms 的延迟(额外多出约 5ms 是确保 SUP1 更早到达)。至于声压级,因为两者在你的位置相差小于 10 dBA,所以理论上不用调整,当然,适当提高 SUP1 以将差距缩小至 6 dBA 也是可行的。
到这里,我们只考虑了你的位置。从下面的模拟计算可以看到,施加 17ms 延迟后,场景中仍有 33% 的座位不能正确判断声音来源。
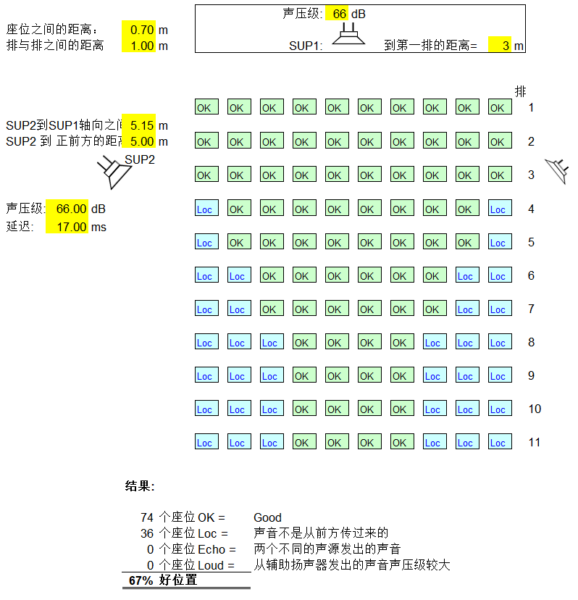
我们还需要考虑最后一排的情况。通过计算,将 SUP2 的延迟设置为 21ms 即可保证全场位置都不受干扰。
很显然,现实中的情况要复杂得多,扩声系统的规模可能远超普通人的想象,音响工程师们要纵观全局。
借助 XL2 分析仪这样的专业仪器,可以很轻松的直接测量延迟和声压级差,从而快速修改设置。

空间音频
以上讨论的都是存在多声源的场景,对于单一声源,我们能做到快速定位主要得益于头部的存在 - 因为头部的掩蔽效应,一个声音到达左右耳的时间一般也不相同。
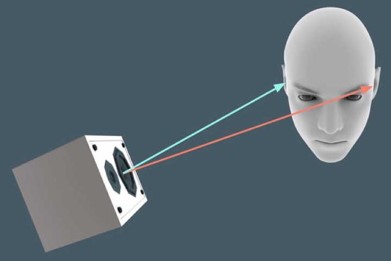
通过声压级差和时间差,我们可以有效控制人在水平方向上的声音定位。但如果声音是从人的正上方或下方传来,双耳时差将不复存在 - 垂直方向甚至全面的空间定位,情况要复杂的多。
我们在之前关于“为什么狗狗总喜欢歪着头”的内容中解释过,人对声音垂直方向的定位需要借助外耳廓的声反射,这种反射声会造成细微的频谱辅助信息的改变,从而帮助我们判断声音的高度。
")
通过采集分析这些频谱辅助信息和人耳定位之间的关系,就能对声源的听感位置实现精准的定量控制。
现在,随着芯片算力的突飞猛进以及建模仿真和 AI 大模型的日益成熟,精准控制声压级、延迟、相位、频谱等音频参数已经成为现实,空间音频技术慢慢在消费类音频产品中普及。

© Apple Inc.
很多产品不仅能实现基本的声源定位,更能追踪人的头部运动和听音环境,并对声音实时渲染,创造出独一无二的“声景观”。只要戴上一副耳机,我们就能身临其境地听一场音乐会。
除了耳机、汽车等相对固定的空间或场景,厅堂这类大空间、多听众的声定位则复杂得多,不过市场上也已经有对舞台人员的声音进行实时定位的解决方案,相信在不久的将来,这样的应用将越来越多。

和灯光类似,声音也可以聚焦在某个人身上
今天的主要内容就是这些,希望对大家有所帮助。
